We are the Frontier of
Document Processing
AI-powered Document understanding, Knowledge Retrieval, and Automation Pipeline from Seoul, Korea.
AI-powered Document understanding, Knowledge Retrieval, and Automation Pipeline from Seoul, Korea.
Iruri Labs builds production-grade document intelligence for teams that must turn real-world paperwork into reliable, structured, and actionable data. We combine semantic document understanding, knowledge retrieval, and workflow automation into a single engine—designed to be accurate, scalable, and easy to integrate.
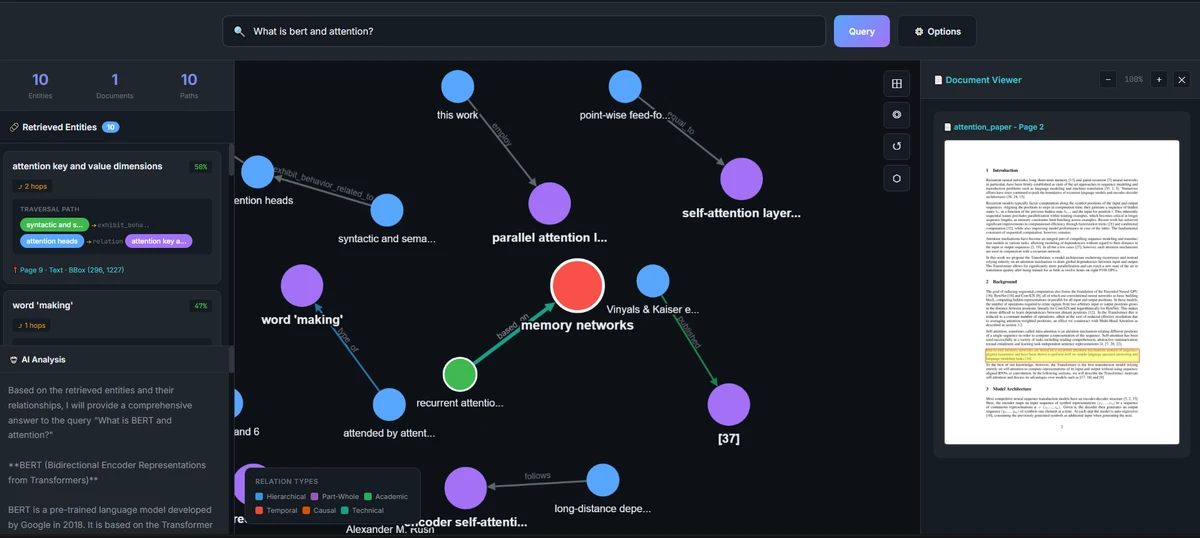
We treat a document not as a flat image, but as a structured space made of semantic regions. As you scroll, the 3D document behind this page splits into paragraphs, figures, tables, and form fields—then connects them as a graph.

Our Retrieval-Augmented Generation stack is built on a Knowledge Graph foundation, with semantic chunking designed for rich documents. It is optimized for precision, ranking quality, and short time-to-confidence.
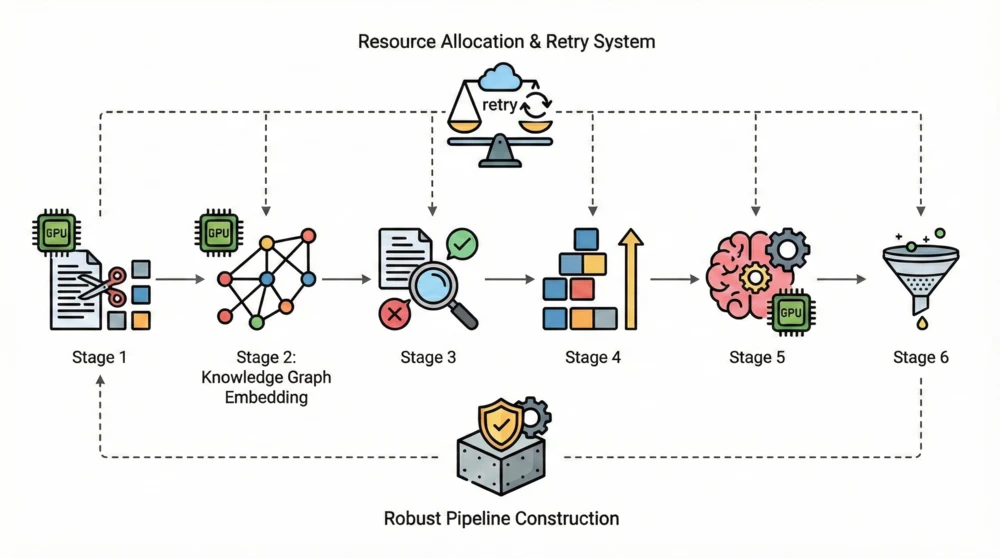
Documents become valuable only when they move through a reliable engine. As you scroll, the 3D document flows through our pipeline—getting parsed, normalized, interpreted, and enriched into machine-usable meaning.
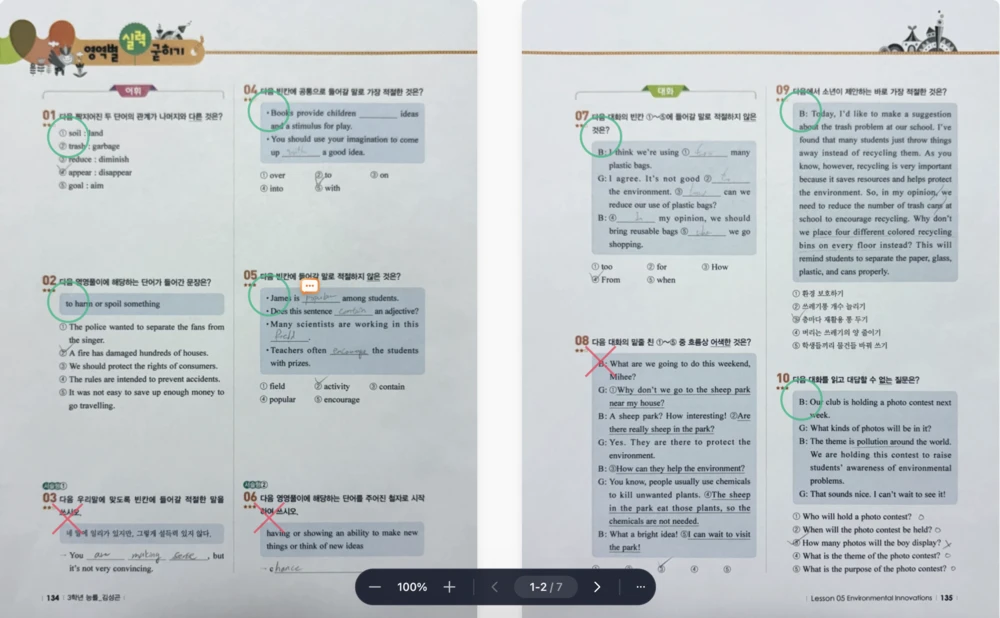
Our flagship product turns any exam paper—commercial, custom-made, or legacy—into a searchable database with minimal change to your existing teaching workflow. Scan or photograph, and we handle the rest: recognition, structuring, grading, and reporting.

Recognize questions and content from virtually any layout. Convert scans and photos into a clean, queryable database.
High-precision scoring for objective formats and handwriting-enabled workflows, with consistency you can audit.
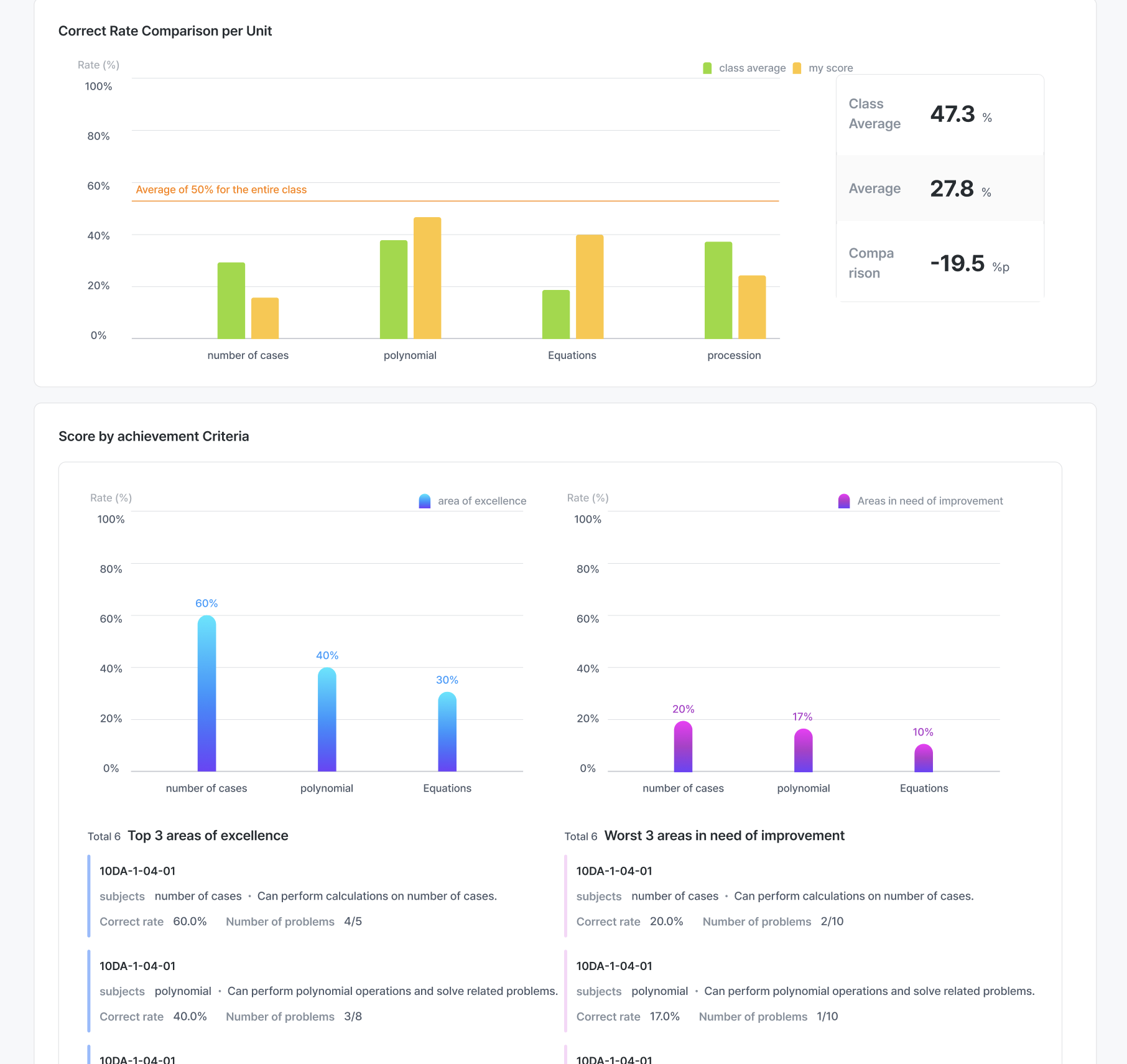
Detailed, report-style feedback that helps instructors maximize learning outcomes and personalize guidance.

Deploy without disrupting your existing class operations. Keep the same teaching style—upgrade the workflow.

Engineers from SNU. Experts in AI, NLP, and Software Engineering.
At the heart of the Asian AI community, pushing through the boundaries of AI.

We work together to solve hard problems.